This week I worked on optimizing the program so that it produces output more efficiently. I did this using Dr. Papamichail's instructions to update the hashes directly instead of rehashing for each new mutated sequence. Additionally, I changed the program so that it only calculated the folding energy of the sequence every 20 trials, although this might also change to something else. I then ran trials of 5000 for more data. Additionally, I added a correlation function that Dr. Papamichail wrote so calculate the correlation.
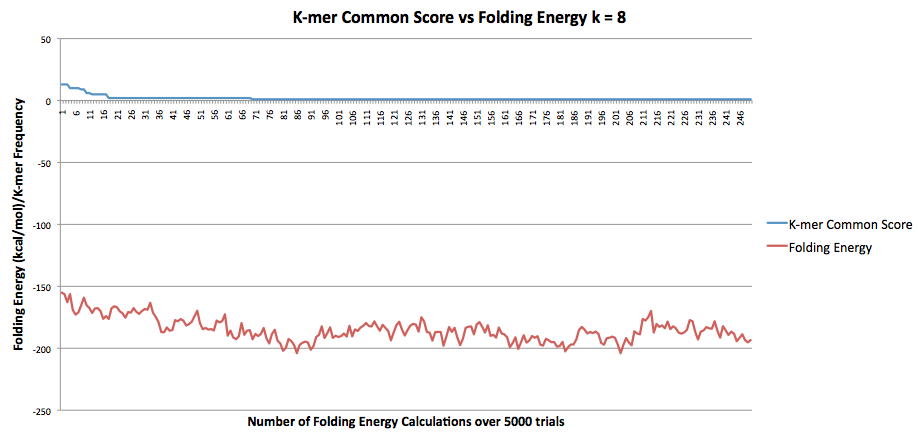
The graph below represents the k-mer common score where k = 5 and the folding energy for each time the folding energy was calculated. This ended up being a total of 250 times over 5000 trials. The correlation was
r = 0.738168483244631.
The graph below represents the k-mer common score where k = 5 and the folding energy for each time the folding energy was calculated. This ended up being a total of 250 times over 5000 trials. The correlation was
r = 0.738168483244631.
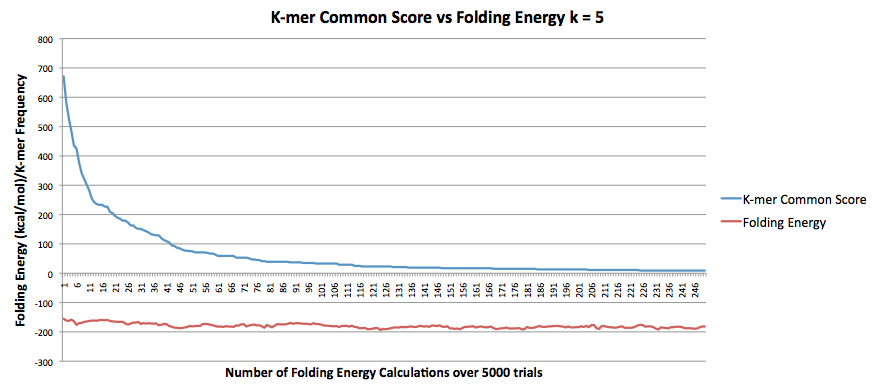
This next graphs show the same information as the graph above but for k values of k=6, k=7, and k = 8. Each graph title shows the k-value. The correlation for k = 6 was r =0.374045002925476.
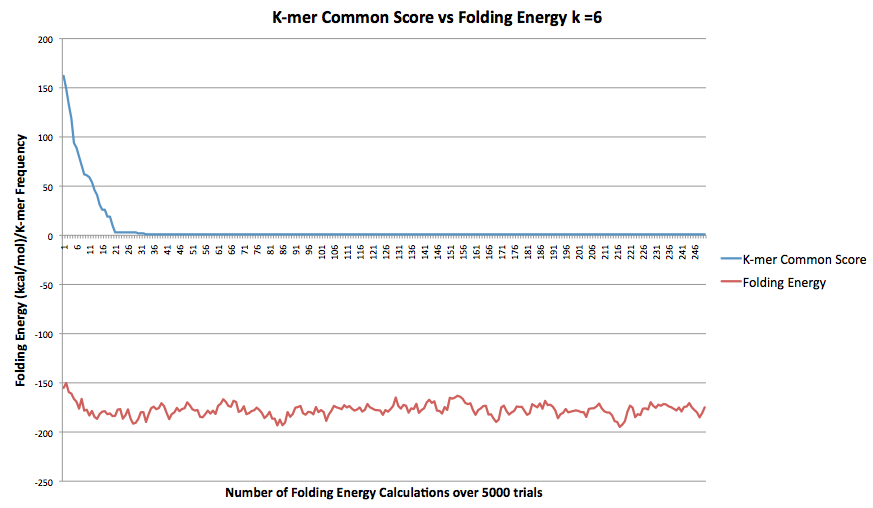
The correlation for k=7 was r = 0.410242405536115.
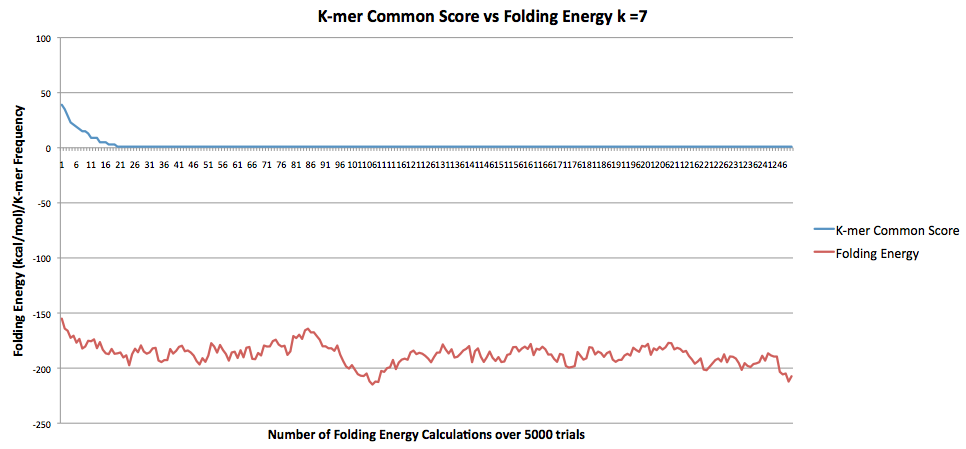
The correlation for k=8 was r = 0.621271542552526.